Building an AI Music Rap Generator with Azure ML and NVIDIA A100 GPUs.
1261 words • 7 min read
Building an AI Music Rap Generator with Azure ML and NVIDIA A100 GPUs
Creating music with artificial intelligence is no longer science fiction—it's an exciting reality that I'm currently exploring through my latest research project. In this post, I'll share my journey of building an AI-powered rap music generator using some of the most advanced machine learning infrastructure available today.
🎵 The Vision
The goal was ambitious: create an AI system capable of generating original rap music, complete with beats, lyrics, and vocal synthesis. Not just random noise, but coherent, rhythmically sound music that captures the essence of rap as a genre.
🚀 Why This Project?
Rap music presents unique challenges for AI generation:
- Complex rhythmic patterns - Rap relies heavily on intricate timing and flow
- Lyrical coherence - Words must make sense and tell a story
- Cultural context - Understanding references, wordplay, and style
- Audio quality - Production value matters in modern music
These challenges made it the perfect testing ground for exploring the boundaries of AI-generated content.
☁️ Azure ML Infrastructure
One of the biggest enablers for this project was Azure's sponsorship providing access to NVIDIA A100 GPU engines. These aren't your typical consumer GPUs—A100s are data center-grade accelerators designed specifically for AI workloads.
 Azure ML training dashboard showing real-time metrics from A100 GPU clusters
Azure ML training dashboard showing real-time metrics from A100 GPU clusters
Why A100 GPUs Matter
The NVIDIA A100 offers:
- 312 teraflops of deep learning performance
- 40GB or 80GB of high-bandwidth memory
- Multi-Instance GPU (MIG) technology for efficient resource utilization
- Third-generation Tensor Cores optimized for AI training
For audio generation, these specs translate to:
- Faster training iterations
- Ability to process longer audio sequences
- More complex model architectures
- Real-time inference capabilities
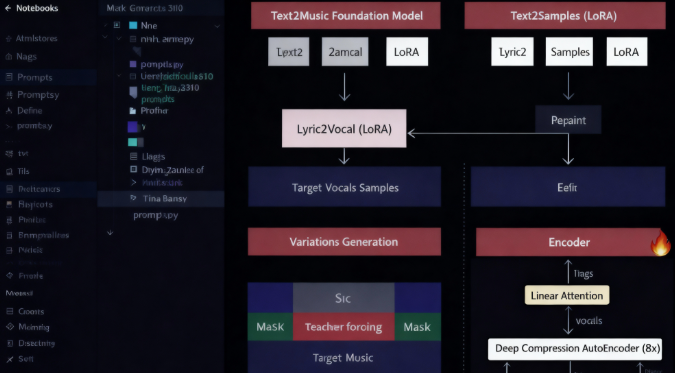
🎼 The ACE Step Model
At the heart of the system lies the ACE (Audio Continuation Engine) step model architecture. This approach breaks down audio generation into manageable steps:
 Visualization of the ACE step model generation pipeline and architecture
Visualization of the ACE step model generation pipeline and architecture
How ACE Works
- Conditional Input - The model takes a prompt (lyrics, style, tempo)
- Latent Representation - Audio is encoded into a compressed latent space
- Step-by-Step Generation - Audio is generated incrementally, not all at once
- Diffusion Process - Noise is gradually refined into coherent audio
- Decoding - Latent representations are converted back to audio waveforms
This architecture allows for:
- Better control over generation parameters
- Higher audio quality
- More coherent long-form compositions
- Style transfer capabilities
🧠 Research Focus Areas
My research explores several critical aspects of AI music generation:
1. Rhythm Pattern Recognition
Teaching the AI to understand and generate proper rap flow requires analyzing thousands of tracks to identify:
- Beat placement patterns
- Syllable timing
- Flow variations
- Tempo changes
2. Lyrical Coherence
Using natural language processing to ensure generated lyrics:
- Maintain thematic consistency
- Follow proper rhyme schemes
- Create meaningful narratives
- Use appropriate vocabulary
3. Voice Synthesis
Generating realistic vocal performances involves:
- Pitch control
- Timbre variation
- Emotional expression
- Breath and articulation modeling
4. Style Transfer
Enabling the model to:
- Adapt to different rap styles
- Mimic particular artists (ethically)
- Blend multiple influences
- Create unique hybrid styles
🛠️ Technical Stack
The project leverages a modern ML technology stack:
Infrastructure:
- Azure Machine Learning Studio
- NVIDIA A100 GPU clusters
- Docker containerization
- Azure Blob Storage for datasets
Frameworks:
- PyTorch - Primary deep learning framework
- TensorFlow - Complementary tools and models
- Librosa - Audio processing and feature extraction
- SoundFile - Audio I/O operations
Model Components:
- Transformer-based architectures
- Diffusion models for audio synthesis
- LSTM networks for sequence modeling
- GANs for quality refinement
 Real-time audio synthesis and generation interface showing waveform outputs
Real-time audio synthesis and generation interface showing waveform outputs
📊 Training Process
Training an AI music generator is computationally intensive:
Dataset Preparation
- Collected and curated thousands of rap tracks
- Extracted vocal stems using source separation
- Transcribed lyrics and annotated timing
- Labeled styles, tempos, and characteristics
Model Training
- Pre-training on general audio data
- Fine-tuning on rap-specific datasets
- Reinforcement learning for quality improvement
- Human feedback integration for refinement
Performance Metrics
Evaluating generated music requires multiple approaches:
- Technical metrics - Signal-to-noise ratio, frequency response
- Perceptual metrics - Human listening tests, preference studies
- Coherence scores - Lyrical and musical consistency
- Originality measures - Similarity to training data
🎯 Challenges Faced
The journey hasn't been without obstacles:
1. Audio Quality vs. Generation Speed
High-quality audio requires processing massive amounts of data, making real-time generation challenging. Balancing quality with latency is an ongoing optimization problem.
2. Lyrical Creativity
While the model can generate grammatically correct lyrics, ensuring they're creative and culturally relevant is difficult. This requires sophisticated context understanding.
3. Ethical Considerations
AI-generated music raises questions about:
- Copyright and ownership
- Artist attribution
- Authenticity in art
- Potential misuse for deepfakes
4. Resource Management
Even with A100 access, training runs can take days. Efficient hyperparameter tuning and resource allocation are crucial.
🔮 Future Directions
The project continues to evolve with several exciting directions:
Short-term Goals
- Improve generation speed for real-time performance
- Expand style diversity beyond rap
- Implement user-friendly interface
- Add collaborative features for human-AI music creation
Long-term Vision
- Full album generation capabilities
- Multi-track production (beats, vocals, instruments)
- Emotional control and storytelling
- Integration with music production DAWs
💡 Key Takeaways
Building an AI music generator has taught me valuable lessons:
- Hardware matters - Access to A100 GPUs dramatically accelerated development
- Interdisciplinary knowledge - Success requires understanding both ML and music theory
- Iteration is key - Continuous experimentation and refinement lead to breakthroughs
- Community input - Feedback from musicians and listeners is invaluable
- Ethical responsibility - AI creators must consider the implications of their work
🌟 The Bigger Picture
This project represents more than just generating music—it's about exploring the creative potential of AI. While machines may never fully replicate human creativity, they can become powerful tools for artists, democratizing music production and opening new avenues for expression.
The collaboration between Azure's infrastructure support and NVIDIA's cutting-edge hardware has made this research possible, demonstrating how industry partnerships can accelerate innovation in AI research.
🔗 What's Next?
I'm continuing to develop this project and will share updates as progress is made. If you're interested in AI-generated music, machine learning research, or have feedback on this project, I'd love to hear from you!
Tech Stack Highlights:
- Azure Machine Learning
- NVIDIA A100 GPUs
- PyTorch & TensorFlow
- ACE Step Model Architecture
- Docker & Python
Research Areas:
- Audio synthesis
- Natural language processing
- Rhythm pattern recognition
- Style transfer learning
Have questions about this project? Connect with me on GitHub or reach out via the contact page.
📚 Resources & Further Reading
If you're interested in diving deeper into AI music generation, here are some resources I found valuable:
-
Research Papers:
- "Jukebox: A Generative Model for Music" (OpenAI)
- "MusicLM: Generating Music From Text" (Google)
- "Diffusion Models for Audio Generation"
-
Tools & Libraries:
-
Communities:
- r/MachineLearning
- AI Music Creation Discord servers
- Azure ML Community Forums
Last updated: October 21, 2025